Kyle Keough
Kyle Keough
The general overview for the approach to this project was to create a logistic regression that both predicted which NBA players were either in the hall of fame or would be inducted into the hall of fame, as well as the probability of them being there (in other words on a scale from 0 to 1 how much do the "look like" a hall of famer). The main steps would be to scrape any needed player and team data from basketball reference, format and clean the data, and run scikit learn and keras logistic regression models for comparisons sake. On that note, I’ll get into the details of the process and the end results.
The general plan was to load and clean all data in one notebook (could have also been handled in a script) where the necessary dataframes would then be stored in pickle files. This would allow for another notebook to handle visualization and modeling without having to repeatedly run the initial scraping and cleaning steps. The data would be collected from a combination of one Kaggle dataset containing individual player statistics, scraped data from basketball-reference.com for team statistics and season awards, as well as a list of hall of fame players from the ever reliable Wikipedia. I would use BeautifulSoup in order to parse all of the data located on the web, and seeing as the structure was unique for most basketball reference pages with occasional blank/erroneous rows and columns different syntax was needed to read in different frames. After some EDA and testing with models the team statistics did not end up being used in final models, but could be useful for future analyses. Sparing the details of going through every aspect of the data preparation, column datatypes were adjusted to prepare for calculations later, dataframes were merged to create one inclusive data source, apply was used to calculate advanced metrics as new columns and ultimately data was saved as pickle files. These statistics would then be normalized in the next notebook to account for the discrepancy between certain values (i.e. championships being 3 and field goal percentage being 0.5).
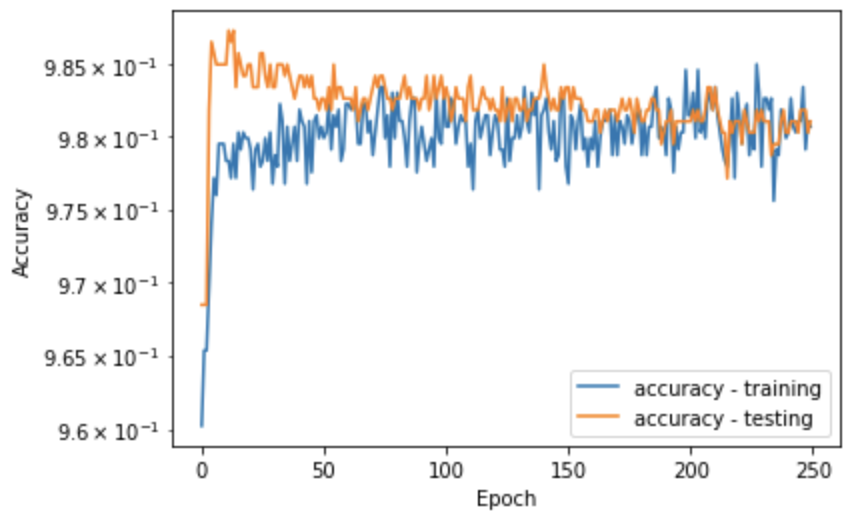
One thing to consider when attempting to compare NBA players of different eras is that certain statistics and awards have not been present throughout all eras, one of the most notable ones being the 3 point shot. There was also a separation of players between the ABA and NBA which causes some issues with the model, this will be addressed further later on. Before accounting for these various factors, the first model created was a simple logistic regression with a large number of features that did not account for era discrepancies; this model would essentially serve as a baseline. As stated before, all features were scaled to account for large variability in the range of different values, and the target would be set as the binary yes or no (0 or 1) for hall of fame induction status. After splitting data into train and test sets using scikitlearn, training the model and testing against the actual dataset, this simple model performed well based solely on the final accuracy score with ~97.9%. This needs to come with a large grain of salt, however, due to how overwhelmingly sparse the number of hall of fame players actually is. With such a large majority of players being very clearly outside of the hall of fame, by just getting the “gimme” predictions correct and performing poorly on hall of fame inductees and fringe players, a model can still produce a high accuracy score. Regardless of this we still have a good starting point to build off of here. After looking at how coefficients impacted the initial results, considering possibly correlated features (such as combinations of field goals made, free throws made, and total points), and considering era agnostic features, a new set was created. This new set of features was centered mainly around career averages, season awards, and championships won. Again I would start with a more basic scikit learn logistic regression model, this time running GridSearchCV to find the best parameters for our model (in this case only needing to check C). This time around there was a slight uptick of 0.3% accuracy, which is actually quite significant with how few hall of famers are present. Now using these features to train our final model, Keras would be used as a deep learning solution to iterate over many epochs and hopefully produce our most accurate results. The Keras model was created as a sequential model (each hidden layer connects to the next in a linear sequence) with a dropout of 0.3 to account for overfitting and 2 hidden layers with relu (was more accurate than sigmoid in this case) activation functions. The target layer would use binary cross-entropy as its loss function (works very well with binary classification) and an adam optimizer for a good general solution. After landing on a 0.333 validation split and running our model for 250 epochs, the final model could be analyzed. Once again there was an increase in accuracy of 0.2%, but this time digging a little deeper with scikit learns confusion matrix function gives a more in depth idea of the results. The sensitivity of the results, or the percentage of players in the hall of fame that the model guessed correctly, is roughly 76%. While this isn’t great off the bat, we once again have to dig a little bit deeper. For starters, 17 of the incorrectly guessed hall of famers are players who were ineligible when this model was made, but are very likely hall of famers. This brings our sensitivity to over 90%. Our initial specificity, or the percentage of non hall of famers that our model correctly guessed, is roughly 99%. Again this is in large part due to the fact that there are so many negatives in this model, but on top of this 11 players were found to be outside the scope of the model due to their successes coming largely in the ABA or internationally, improving the specificity even more. All things considered, the actual yes or no of the model performed very well, but the actually probabilities assigned to each player is where I thought all the fun of this project came from, so some selections of those will be listed below.
The full data loading notebook can be found at:
NBA HOF data loading and cleaning Github Repo
The full modeling notebook can be found at:
NBA HOF model training Github Repo
| Player Name | Hall of Fame Probability |
|---|---|
| Julius Erving | 0.9945 |
| Bill Russell | 0.9769 |
| John Havlicek | 0.9740 |
| Kareem Abdul-Jabbar | 0.9705 |
| Wilt Chamberlain | 0.9646 |
| George McGinnis | 0.9562 |
| Jerry West | 0.9534 |
| Elgin Baylor | 0.9519 |
| Connie Hawkins | 0.9498 |
| Zelmo Beaty | 0.9446 |
| Elvin Hayes | 0.9424 |
| Tom Heinsohn | 0.9371 |
| Sam Jones | 0.9321 |
| Artis Gilmore | 0.9285 |
| Dolph Schayes | 0.9246 |
| Magic Johnson | 0.9186 |
| Bob Pettit | 0.9158 |
| LeBron James | 0.9106 |
| Oscar Robertson | 0.9106 |
| Bob Cousy | 0.9062 |
| Dave DeBusschere | 0.9038 |
| Larry Bird | 0.8937 |
| Wes Unseld | 0.8904 |
| Patrick Ewing | 0.8869 |
| Walt Frazier | 0.8804 |
| Player Name | Hall of Fame Probability |
|---|---|
| Tony Parker | 0.8585 |
| Tim Duncan | 0.8421 |
| Chris Bosh | 0.8378 |
| Pau Gasol | 0.8117 |
| Larry Foust | 0.8054 |
| Player Name | Hall of Fame Probability |
|---|---|
| Roger Brown | 0.0029 |
| Louie Dampier | 0.0052 |
| Tracy McGrady | 0.0121 |
| Arvydas Sabonis | 0.0130 |
| John Thompson | 0.0156 |